
Article mis à jour le 20 juin 2023.
J’ai assisté à un webinar Cloudera sur le tuning des performances d’applications Spark proposé par François Reynald, un des Senior Technical Instructor de Cloudera. Il a d’ailleurs écrit cet article sur comment Spark 3 améliore les performances des SQL workloads.
Et dans l’un des précédents articles du blog Cyrès, j’avais évoqué les principales nouveautés de Spark 3. L’une d’entre elles est l’Adaptive Query Execution (AQE). Cet article portera donc sur cette optimisation, la motivation, les challenges et solutions que l’AQE propose. De plus, cet article couvrira plus en détail ce point : la fusion dynamique des shuffle partitions.
Bref historique de l’AQE pour Spark
L’idée d’une planification ou exécution de requête adaptif était un sujet de recherche pendant des années ; Spark avait introduit ce concept avec sa version 1.6 même si c’était limité. Spark est souvent associé à la vitesse et à la haute-performance, ce besoin de toujours mieux performer et d’aller plus vite est la motivation derrière la conception de l’AQE.
Pour être performant, le moteur de Spark avait besoin d’être plus intelligent sur la phase de planification de requête (query planning), ça veut dire qu’il fallait s’attaquer aux plus grandes limitations de l’architecture de l’époque :
- La première limitation était que le moteur de Spark nécessitait que les instructions d’exécution pour un job soient définies en avance ; ce qui veut dire qu’il était difficile de prédire le comportement de la donnée et des fonctions utilisateurs (UDF) pour générer des plans d’exécution plus optimaux durant le runtime.
- Une autre limitation était que, puisque Spark exploite un framework d’optimisation basé sur les coûts qui collecte une variété de statistiques de données ; des statistiques obsolètes et des estimations de cardinalité imparfaites peuvent se produire, ce qui conduit à des plans de requêtes sous-optimaux.
Ayant pour but de remédier à ces limitations en ré-optimisant et en ajustant les plans de requête basés sur les statistiques du runtime, l’équipe Big Data Intel avec Databricks ont prototypé et expérimenté une version plus avancée de l’AQE et ont fini par la livrer dans Spark 3.0.
Qu’est-ce que l’AQE et pourquoi en a-t-on besoin ?
Pour définir formellement l’AQE, je vais citer Maryann Xue (https://databricks.com/speaker/maryann-xue) lors du talk « Adaptive Query Execution : Speeding Up Spark SQL at Runtime » du Spark + IA Summit 2020 :
« AQE is a query re-optimization that occurs in query execution (…) [It] is a dynamic process of query optimization that happens in the middle of the query execution using runtime statistics as it’s optimization input. »
Traduction : AQE est une ré-optimisation de requête qui se produit lors d’une exécution de requête (…) C’est un processus dynamique d’optimisation de requête qui se déclenche au beau milieu de l’exécution de requête en utilisation les statistiques du runtime en tant que données d’entrée pour optimisation.
Avec des termes plus simples, il s’agit d’une optimisation du plan d’exécution de requêtes que le planificateur de requêtes Spark utilise pour de meilleurs plans d’exécution durant le runtime, en se basant sur des statistiques collectées pendant l’exécution.
Ces adaptations ont été conçues pour obtenir de meilleures performances et un meilleur parallélisme tout en diminuant les efforts fournis pour le tuning de configurations. Spark, comme beaucoup de moteurs de traitements de données / frameworks, a très peu de connaissance sur la donnée avant d’en commencer son traitement et de ce fait, un job pourrait faire face à ces difficultés :
- Nombre incorrect de partitions shuffle
- Choix de stratégies de jointure incorrect
- Datasets mal répartis (data skewness)
- Obtention de plans physiques optimisés
Spark 3 : Framework AQE
Jusque-là on comprend que l’AQE est une sorte d’optimisation qui se produit pendant la phase d’optimisation de requêtes. Mais nous n’avons toujours pas saisi où et quand cela se produit.
Pour y répondre il faut comprendre ces détails du pipeline de traitement Spark :
- Spark combine souvent plusieurs opérateurs en un « whole-stage codegened task »
- Des opérations de shuffle et d’échanges divisent les pipelines en étapes de requête (stages) car il n’y a pas suffisamment de données dans le nœud worker pour finaliser la tâche donnée par le driver
- Chaque étape de requête engendre une matérialisation d’un résultat intermédiaire
- Quand une étape de requête se lance, les étapes suivantes ne peuvent pas se déclencher tant que tous les traitements parallèles de matérialisation n’ont pas été complétés
Le dernier détail évoqué est une limitation de taille, il y a donc une opportunité d’optimisation à saisir. Dans ce cas, cette opportunité se trouve dans la collection de statistiques de toutes les partitions avant que des opérations successives démarrent :
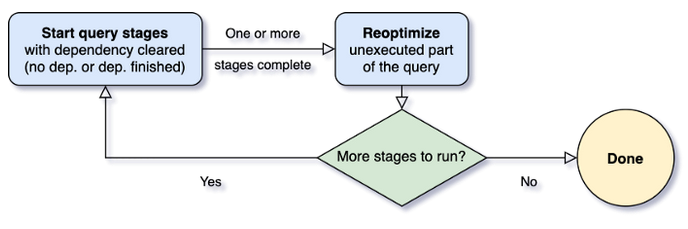
Les détails les plus pointilleux de l’AQE sont mieux expliqués dans cet article de Databricks. Et pour référence, je vais en citer une petite partie (traduite) :
‘”Lorsque la requête démarre, l’AQE lance d’abord toutes les étapes feuilles – les étapes qui ne dépendent d’aucune autre étape. Dès qu’une ou plusieurs de ces étapes ont terminé leur matérialisation, le framework les marque comme terminées dans le plan de requête physique et met à jour le plan de requête logique en conséquence, les statistiques d’exécution étant extraites des étapes terminées.
Sur la base de ces nouvelles statistiques, le framework exécute ensuite l’optimiseur (avec une liste sélectionnée de règles d’optimisation logiques), le planificateur physique, ainsi que les règles d’optimisation physique, qui incluent les règles physiques régulières et les règles spécifiques à l’exécution adaptive, comme la fusion des partitions, la gestion des jointures obliques, etc. Maintenant que nous avons un plan de requête nouvellement optimisé avec quelques étapes terminées, le framework AQE recherchera et exécutera de nouvelles étapes de requête dont les étapes enfants ont toutes été matérialisées, et répéter tout le processus « exécuter-ré-optimiser-exécuter » jusqu’à ce que la requête entière soit terminée.”
Pour répondre à la question “où l’AQE se branche ?”, nous devons regarder le mécanisme d’exécution global de Spark SQL. Comme nous l’avons défini au préalable, AQE est une optimisation d’un plan d’exécution de requête, il est donc naturel de penser que sa place se trouve dans l’étape d’optimisation logique :
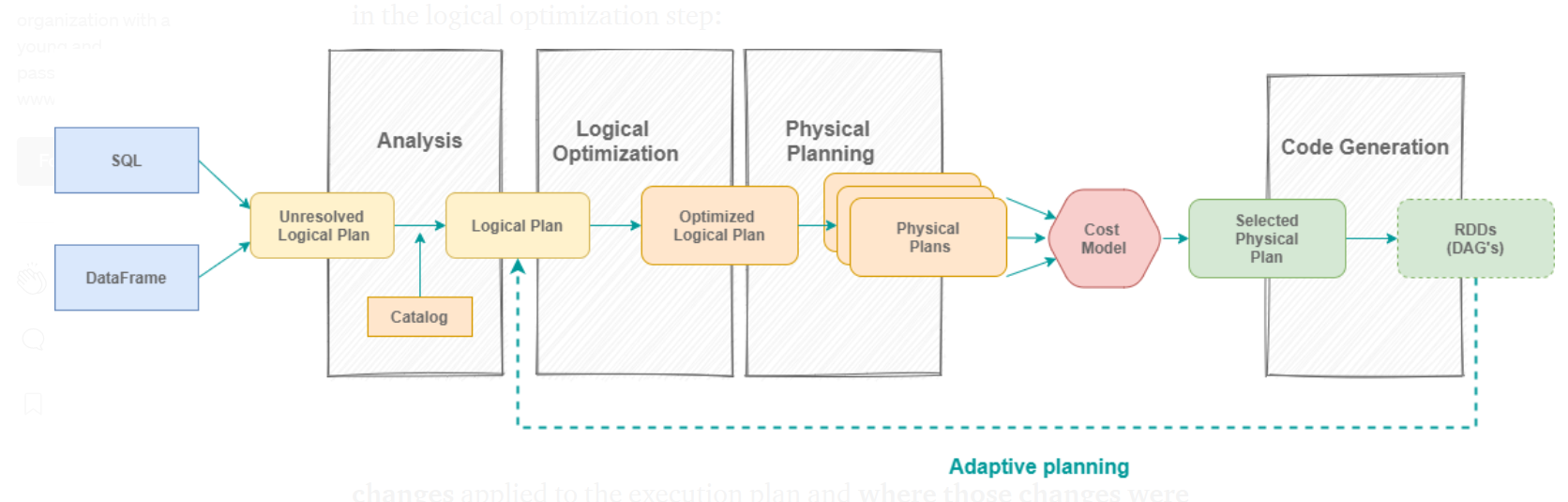
Une fois que le plan d’exécution physique a été sélectionné, le DAG des RDD est généré, les étapes sont créées par le Spark Scheduler aux limites du shuffle, puis soumises pour exécution. Vu que le plan d’exécution ne peut pas être mis à jour durant l’exécution, l’idée de l’AQE est de séparer le plan logique en plusieurs étapes aux limites du shuffle.
Ci-dessous, voici un diagramme illustrant un plan d’exécution avec et sans AQE, adapté depuis des slides de Databricks
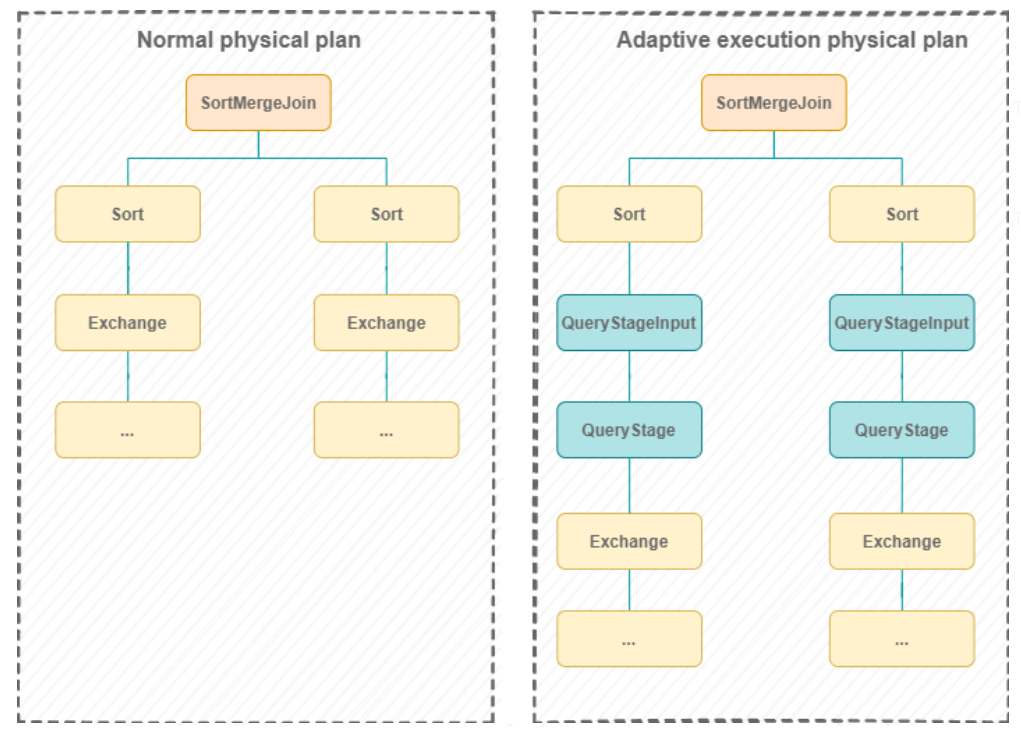
On peut voir à quoi ressemble un plan physique avec et sans AQE. On comprend que le plan d’exécution est divisé en plusieurs « QueryStages » aux limites du shuffle. C’est en fait un des changements majeurs que l’AQE a appliqué dans le framework Spark, mais ceci soulève la question suivante : qu’est-ce qu’un QueryStage et un QueryStageInput ?
- Un QueryStage représente un sous-arbre qui tourne dans une seule étape et a des nœuds feuille appelés QueryStageInput. Le QueryStage matérialise son résultat à la fin de son exécution
- Un QueryStageInput est un nœud enfant du QueryStage et il peut y avoir de multiples nœuds enfants. Chaque QueryStageInput cache ses étapes enfants du nœud parent et récupère seulement les résultats de ses étapes enfants en tant que donnée d’entrée pour le QueryStage
Les QueryStages sont créées via les étapes suivantes :
- D’abord l’arbre de requête est parcouru de bas en haut
- Si un nœud « exchange » (revoir le diagramme de la Figure 3) est atteint et que ses enfants QueryStages sont déjà créées, alors un nouveau QueryStage est créé pour ce nœud
- Si un QueryStage génère son résultat, le reste de la requête est à nouveau optimisé et planifié via les dernières statistiques produites par les stages matérialisés
- Répéter les étapes ci-dessus jusqu’à que toutes les QueryStages aient été créées
- Exécuter ce qui reste du plan
Vous vous intéressez également aux problématiques d’architectures complexes ?
>> Lisez notre article ci-dessous sur les architectures Lamda👇 !
Le challenge du shuffle partition
Maintenant que nous avons parlé des motivations derrière la conception de l’Adaptive Query Execution, nous allons nous pencher sur un des challenges que l’AQE chercher à résoudre : le nombre incorrect de shuffle partitions pendant le runtime.
Pour mieux expliquer ce que ce challenge est, nous allons tenter de l’illustrer par un exemple. Dans le diagramme ci-dessous, on peut voir un mécanisme typique de shuffle dans Spark, où deux Mappers divisent leurs données en 4 parties et 4 Reducers récupérant leur partie de données.
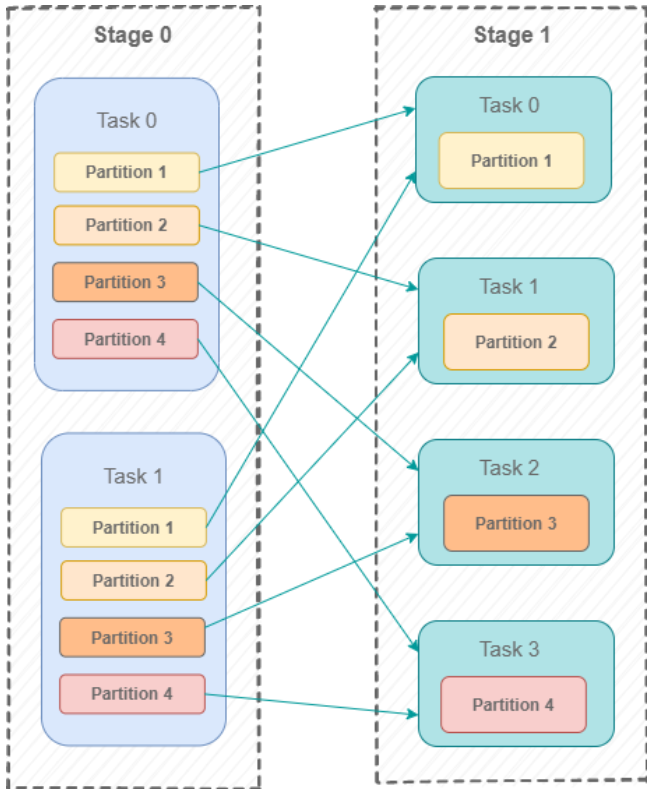
Dans Spark SQL, le nombre du shuffle partition est le nombre de partitions qui sont utilisées quand on shuffle la donnée pour de larges transformations, telles que les jointures ou les agrégations. Les larges transformations se produisent quand des informations venant d’autres partitions sont nécessaires pour obtenir le résultat désiré.
Donc une bonne façon de relier ces informations à l’exemple ci-dessus est de considérer le nombre de shuffle partitions comme le nombre de Reducers ci-dessus, qui est de 4.
Par défaut, le nombre est paramétré à 200 et il peut être ajusté en changeant le paramètre « spark.sql.shuffle.partitions ». Cette méthode de gestion de shuffle partition a quelques problèmes :
- S’il y a un data skew important, certaines tâches peuvent prendre trop de temps dans leur réalisation par rapport à d’autres tâches, ce qui cause une mauvaise utilisation des ressources, ainsi que des temps élevés d’exécutions de stages
- Trop de partitions sur de petites données entraîne une surcharge de planification car il y a beaucoup de tâches Reduce. Les Reducers produiront des petits fichiers, ce qui causera une congestion du réseau lorsque les petits fichiers seront lus plus tard
- Trop de données dans peu de partitions augmente la charge par exécuteur, abaisse le parallélisme, les tâches Reduce devront traiter plus de données, la donnée peut déborder sur le disque vu que la mémoire ne peut pas contenir toute la donnée. Des problèmes de type Out Of Memory peuvent survenir.
- Les shuffles ne seront pas optimaux car chaque shuffle correspond à différentes tailles de données. De ce fait, le nombre optimal de partitions ne sera pas exact.
On comprend le problème maintenant, n’est-ce pas ? Quel est donc la solution ?
Solution : Fusion (coalesce) dynamique Spark des shuffle partitions
La fusion (ou coalesce) dynamique des shuffle partitions est une optimisation logique qui vise à minimiser le nombre de tâches Reduce lors d’un shuffle. Pour expliquer le mécanisme de cet algorithme, nous allons reprendre le diagramme de la section précédente et y ajouter la taille des partitions dans les Reducers pour mieux illustrer la solution :
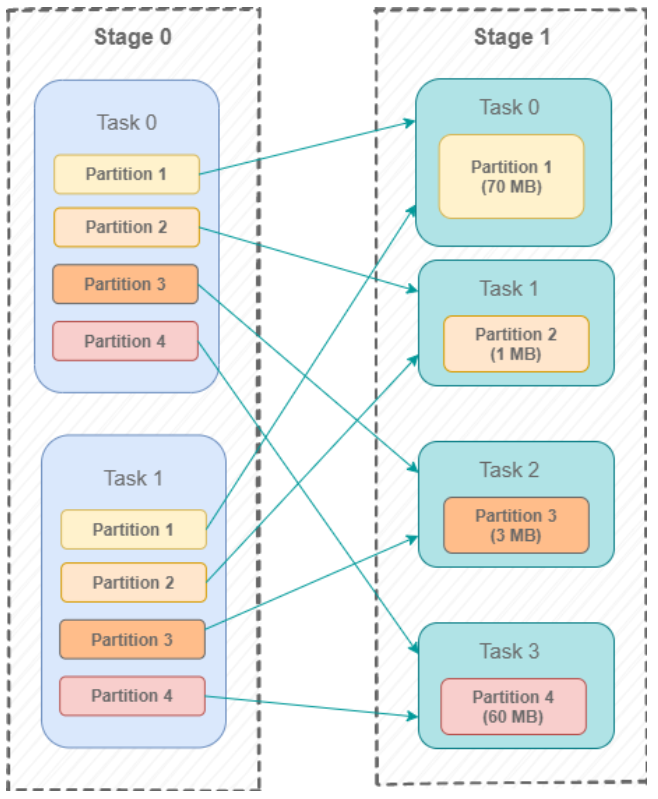
Dans cet exemple, on peut voir que la taille des données de certaines partitions est petite comparée à d’autres, notamment la partition 2 et 3 avec respectivement 1 Mo et 3 Mo.
Pour uniformiser la taille des partitions, l’algorithme de fusion dynamique shuffle partitions part de ces principes :
- La partie Map du shuffle devrait produire un nombre approximatif de bytes de sortie pour chaque partition. Chaque Mapper devrait sortir le volume de chaque partition, ce qui arrive dans ce cas à la fin du Stage 0
- Le nombre minimal de partitions qui devrait être crées doit être calculé. Ce nombre est basé sur le paramètre « spark.sql.adaptive.coalescePartitions.minPartitionNum ». Si cette configuration n’est pas définie, alors pour éviter des problèmes de performance, le nombre minimal de partitions sera la même que celle du parallélisme par défaut (spark.default.parallelism)
- Les différentes partitions avec le même index seront lues dans la même tâche et tous les shuffles ont le même nombre de partitions. Pour déterminer le nombre de partitions fusionnées, une taille cible pour une partition fusionnée est définie avec la configuration « sparl.sql.adaptive.advisoryPartitionSizeInBytes » et toutes les statistiques sur la taille des shuffle partitions sont collectées
- Les partitions ayant le même index sont fusionnées en une seule partition jusqu’à ce que l’ajout de nouvelles shuffle partitions entraîne une taille combinée de la partition fusionnée supérieure ou égale à la taille cible
Nous allons maintenant détailler les étapes de cet algorithme. Il est divisé en deux sections :
- Les contrôles de flux
- Les étapes d’exécution de l’algorithme
A noter que ce que suit reste assez haut-niveau, je mets en lien le code source si vous souhaitez vous plonger en détail dans le code.
- Contrôle de flux 1: Vérifie si l’option AQE est vraie
- Contrôle de flux 2: Décide si l’AQE devrait être appliqué au plan d’exécution de la requête en se basant sur le retour de fonction shouldApplyAQE
En d’autres termes, AQE est appliqué quand une des conditions est vraie :
- La configuration spark.sql.adaptive.forceApply est activée
- La requête en entrée est une sous-requête, si c’est le cas, alors l’AQE est déjà en cours d’application dans la requête principale
- La requête contient une sous-requête
- La requête contient des nœuds « Exchange »
- La requête aurait besoin d’ajouter des Exchanges plus tard (ceci se réalise en vérifiant le SparkPlan.requiredChildDistribution)
- Contrôle de flux 3: Décide si le plan de la requête supporte un AQE, en appelant la fonction supportAdaptive. La fonction renvoie True si le plan n’est pas un streaming dataset, ou si la sous-requête ne contient pas une expression Dynamic Partition Pruning (DPP) en attente d’être résolue. Plus d’informations sur le DPP qui est une nouveauté à Spark 3 ici
- Contrôle de flux 4: Vérifie si la configuration a été activée pour la fusion dynamique des shuffle partitions et que tous les nœuds feuilles sont des QueryStages (fonction)
- Contrôle de flux 5: Vérifie si tous les nœuds exchanges présents dans le plan ne sont pas introduits par une répartition, vu que les shuffle exchanges introduits par la répartition n’autorisent pas de manipulation de partition (voir la fonction collectShuffleStages
- Contrôle de flux 6: Vérifie si le RDD d’entrée a au moins une partition et que les nombres de partitions avant shuffle sont les mêmes (ce n’est pas le résultat d’un SortMergeJoin ou d’une union de données agrégées)
Une fois que les contrôles de flux sont passés, l’algorithme de fusion peut tourner, voici les étapes :
- Etape 1 : Détermine le nombre de partitions fusionnées. Pour la déterminer, une taille cible pour une partition fusionnée est définie par la configuration spark.sql.adaptive.advisoryPartitionSizeInBytes
- Etape 2 : Collecte les statistiques de toutes les shuffle partitions
- Etape 3 : Boucle à travers les partitions et leurs statistiques avec des indices continus. Cela signifie que les partitions de différents shuffles seront lues en même temps car la boucle est déterminée par un index de la partition (Voir les principes de l’algorithme cités plus tôt).
- Etape 4 : Vérifie si la taille combinée des partitions ayant le même index est plus grand que la taille cible de la partition après shuffle
- Etape 5 : Si c’est le cas, alors produit un CoalescedPartitionSpec
- Etape 6 : Si ce n’est pas le cas, alors continue de boucler à travers les partitions jusqu’à que la taille cible soit atteint
Ce fut un gros morceau, donc pour mieux visualiser cet algorithme, voici un diagramme, pour l’exemple, on va choisir la taille cible à 70 Mo :
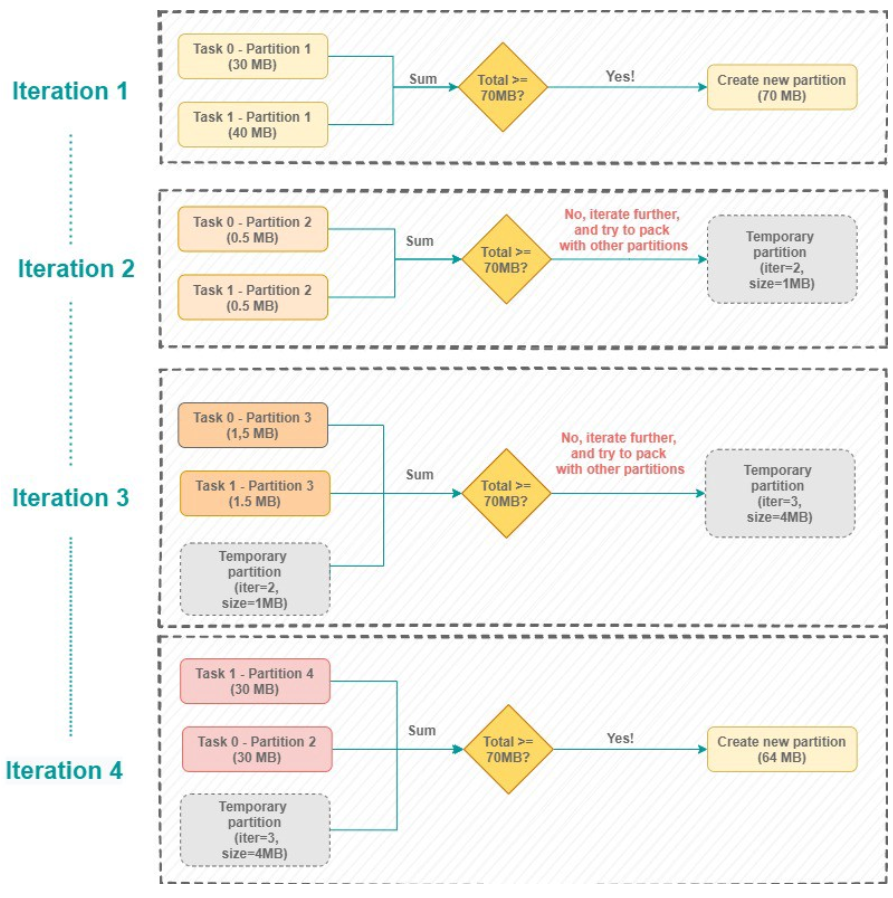
À l’itération 4, la somme des partitions est égale à 64Mo, ce qui est inférieur à la taille cible, mais vu qu’il n’y a plus de partitions sur lequel itérer, une nouvelle partition à 64Mo est créé.
Activer l’optimisation
Maintenant que nous avons détaillé le fonctionnement de la fusion dynamique des shuffle partitions, il est temps de l’activer.
Pour l’activer, il faut configurer 2 propriétés obligatoires et 3 propriétés optionnelles :
- [Obligatoire] La première propriété à paramétrer est spark.sql.adaptive.enabled, à True pour autoriser l’AQE, elle est désactivée par défaut dans Spark 3.
- [Obligatoire] La seconde propriété à paramétrer est spark.sql.adaptive.coalescePartitions.enabled, également à True pour activer l’optimisation de fusion des partitions
- [Optionelle] La troisième propriété à paramétrer est spark.sql.adaptive.coalescePartitions.initialPartitionNum, la valeur étant le nombre de shuffle partitions désiré avant que la fusion ne commence. Cette valeur est par défaut la même que celle de spark.sql.shuffle.partitions. La nouvelle valeur sera prise en compte que si les deux propriétés obligatoires ont été activées
- [Optionnelle] La quatrième propriété à paramétrer est spark.sql.adaptive.coalescePartitions.minPartitionNum, pour déterminer le nombre minimal de shuffle partitions à créer avant que le processus de fusion ne se déclenche. Si elle n’est pas définie, la valeur par défaut est le parallélisme par défaut (spark.default.parallelism) du cluster Spark. La nouvelle valeur sera prise en compte que si les deux propriétés obligatoires ont été activées
- [Optionnelle] La cinquième propriété à paramétrer est spark.sql.adaptive.advisory.PartitionSizeInBytes. Ceci sera la taille cible des partitions fusionnées. La nouvelle valeur ne sera prise en compte que si les deux propriétés obligatoires ont été activées
Conclusion
Partant d’abord de son historique jusqu’à la description de l’algorithme de fusion dynamique, cet article particulièrement fourni avait pour but de clarifier l’optimisation des shuffle partitions et de l’Adaptive Query Execution dans l’architecture globale de Spark. J’espère que cet article vous aura plu ! Voici d’autres articles en lien avec l’AQE pour en apprendre davantage, ou simplement voir d’un autre œil cette puissante optimisation :
- https://www.waitingforcode.com/apache-spark-sql/whats-new-apache-spark-3-shuffle-partitions-coalesce/read#physical_execution
- https://software.intel.com/content/www/us/en/develop/articles/spark-sql-adaptive-execution-at-100-tb.html
- https://medium.com/swlh/spark-sql-adaptive-query-execution-3adc68973c91





