
A l’air du tout automatique, penchons-nous sur une méthode qui fait ses preuves chez nos clients : incorporer Ansible dans les déploiements Big Data.
Pour cette série d’articles nous allons voir comment nous automatisons nos déploiements Big Data avec Ansible.
Episode 2 : Module Ansible HDFS
Contexte
Précédemment nous vous parlions d’une méthode que nous avons mise en place, afin de provisionner Hadoop Hdfs grâce à des tâches Ansible. Retrouvez l’épisode en question ici.
Depuis nous avons travaillé sur des modules Ansible Hdfs afin de profiter de l’idem potence, d’accélérer le développement et rendre nos playbooks / rôles plus lisibles.
Module : hdfs_file
Le premier besoin qui s’est fait ressentir a été d’avoir un module similaire à celui natif d’Ansible : « file ».
Nous allons vous présenter notre module « hdfs_file », nous prévoyons également dans un futur proche les modules : « hdfs_acl » et « hdfs_copy/put ».
Interaction avec le service hdfs
Le paquet python « hdfs » fût dans un premier temps un bon candidat. Finalement, cette méthode s’est vite montrée trop contraignante. Elle nous obligeait:
- L’installation du paquet python chez l’hôte avant l’utilisation du module
- La récupération des configurations Hdfs chez l’hôte ou complexifier les paramètres du module.
- La maintenance fréquente du module pour correspondre aux différentes versions d’Hdfs sur le cluster cible.
- La prise en charge éventuelle d’un ticket Kerberos (en fonction de la configuration du cluster).
A la vue de toutes ces contraintes, l’interaction avec l’interface de commande Hdfs (« bin/hdfs dfs »), malgré quelques défauts, s’est retrouvée sous les projecteurs. Cette solution nous permet de partir du principe que : « si la Command Line Interface fonctionne, notre module aussi ». Cette propriété nous facilite grandement la résolution de problème éventuels de connexion avec le cluster. Nous avons donc naturellement fixé nos positions sur cette solution.
Options du module
Nous avons repris l’esprit du module ‘file’ natif en supprimant les options liées à selinux et aux liens symboliques puis nous y avons ajouté le paramètre réplication, spécifique à Hdfs. Afin de faciliter l’utilisation du module, nous avons essayé de coller au plus près du bultin, voici à quoi cela ressemble:
| parameter | required | default | choices | comments |
|---|---|---|---|---|
| group | no | Name of the group that should own the file/directory, as would be fed to chown. | ||
| method | no | command | command library |
If `command`, this module will manage with the hdfs CLI. If `library`, this module will manage with the hdfs python module. |
| mode | no | Mode the file or directory should be. For those used to /usr/bin/chmod remember that modes are actually octal numbers /usr/bin/chmod remember that modes are actually octal numbers due to CLI limitation (cannot get file mode) | ||
| owner | no | Name of the user that should own the file/directory, as would be fed to chown. | ||
| path | yes | The hdfs absolute path being managed | ||
| recurse | no | no | The module will recursively set the specified file attributes (applies only to state=directory) | |
| replication | no | The replication factor of a file/directory, please not that setting the replication on a directory is always apply recursivly. | ||
| state | no | file | file directory touch absent |
If `directory`, all immediate subdirectories will be created if they do not exist, they will be created with the supplied permissions. If `file`, the file will NOT be created if it does not exist, see the `hdfs_copy` module if you want that behavior. If `absent`, directories will be recursively deleted, and files will be unlinked. Note that `hdfs_file` will not fail if the path does not exist as the state did not change. If `touch`, an empty file will be created if the path does not exist, while an existing file will receive updated file access and modification times (directories stay untouch). Please note that touch update file owner, group, mode and replication, you should set this param explicitly to replace them. |
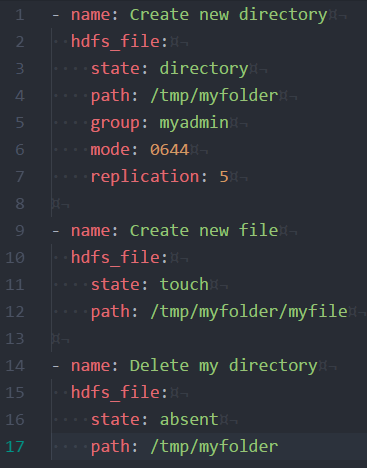
Exemple :
Pour finir voici un petit exemple d’utilisation de notre module afin d’illustrer nos propos.
Si vous êtes intéréssé par ces problématiques, n’hésitez pas à nous contacter, sur notre site, ou sur twitter via @cyresgroupe




