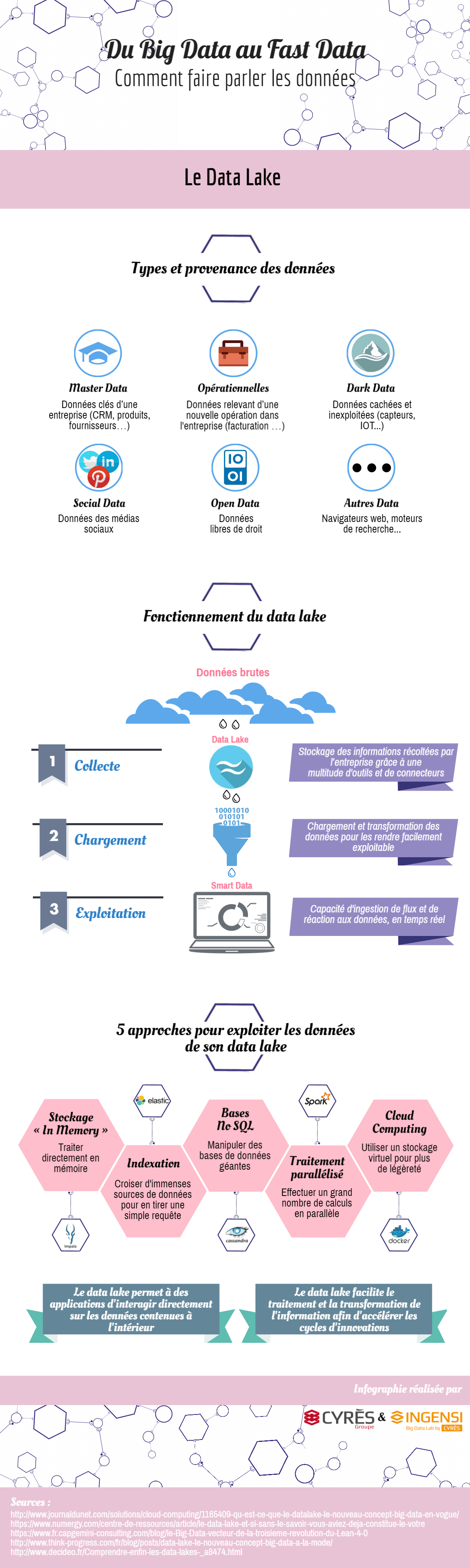
Dans cette seconde partie de notre infographie “Du Big Data au Fast Data”, nous abordons la notion de Data Lake en tant que référentiel de stockage de données, dans le cadre d’un projet Big Data.
Les flux de données brutes déversées dans le data lake de l’entreprise peuvent être très variés. Cela implique, au-delà du chargement des données rendu possible grâce à une multitude de connecteurs, d’appliquer des processus de transformation et d’ordonnancement sur les données récoltées. L’objectif étant de pouvoir interroger le data lake sur un ensemble de données raffinées afin d’obtenir des réponses instantanées.
L’obtention de réponses en temps réel doit enfin permettre à l’utilisateur, à l’issu du processus, de déterminer quelle sera l’action ou la décision la plus opportune à prendre pour atteindre l’objectif final visé dans le cadre d’un projet Big Data.
Ceci nous amènera dans une troisième et dernière partie aux notions de Fast Data et de prédiction en temps réel.
Vous pouvez également retrouver notre infographie sur le site de Frenchweb.
Du Big Data au Fast Data | Comment faire parler les données – Part. 2