
Avec la hausse des données à analyser et donc du besoin en Big Data, les Data Scientists ont de plus en plus besoin d’outils et de plateformes répondant à leurs besoins. Certaines solutions populaires sont déjà bien implantées voire directement intégrées à certains produits informatiques. Comment choisir la bonne solution en fonction des besoins et ressources à notre disposition. Pour essayer de répondre à cette question, nous allons commencer par présenter JupyterHub et la solution de chez Cloudera CDSW (Cloudera Data Science Workbench), leurs méthodes d’installation respectives ainsi que nos retours d’expérience.
Qu’est-ce que JupyterHub ?
JupyterHub est une plateforme de data science qui utilise et regroupe les différentes solutions de la suite Jupyter (https://jupyter.org/ ) (Notebook, Lab, …). Le principe étant de fournir une seule web UI exposée dans laquelle chaque utilisateur peut avoir son ou ses workspaces (appelés également user servers dans l’univers jupyter).
Cette solution encapsule des comptes admin qui facilite grandement le maintien en conditions opérationnelles, améliore la réponse aux demandes et aux problèmes des utilisateurs par les administrateurs de la plateforme.
Les avantages offerts par JupyterHub :
- Customisation : JupyterHub est adaptable à beaucoup d’environnements différents et supporte une grande quantité de Kernels différents. On peut le configurer pour utiliser les interfaces utilisateurs Jupyter Notebook, Jupyter Lab, RStudio, nteract et bien d’autres. Les grandes options de configurations disponibles et les possibilités d’ajout de modules communautaires ou développés en interne en font une solution très modulaire.
- Flexibilité : On peut utiliser un grand nombre de moyens d’authentification différents avec JupyterHub. Aussi, il est possible d’ajouter des modules d’authentification communautaires ou développés en interne pour répondre à des contraintes ou structures existantes. Les méthodes d’authentification externes comme OAuth et GitHub sont aussi utilisables.
- Scalabilité : JupyterHub est utilisable avec des containers et peut être déployé avec Kubernetes. De plus, la scalabilité de cette solution permet de supporter une grande quantité d’utilisateurs.
- Portabilité : JupyterHub est une solution open-source et peut être déployée sur une grande variété d’infrastructures. Notamment, les divers cloud providers du marché, des machines virtuelles ou encore un ordinateur local.
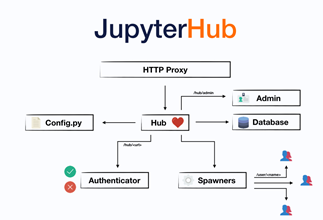
Qu’est-ce que CDSW ?
CDSW est une solution de Cloudera pour répondre au besoin d’une plateforme dédié à la data science dans un environnement Big Data Cloudera. Cette solution est donc parfaitement interconnectée avec les services CDH et autres présents dans un environnement Cloudera.
CDSW se veut rapide, sécurisé et pratique :
- Possibilité d’utiliser R, Python ou Scala avec une connexion rapide et sécurisée vers Spark et Impala.
- Possibilité de partager les workspaces avec les membres de l’équipe
- Mise en production simplifiée
- Configuration de la sécurité et gouvernance dans les workloads
- Utilisable dans les environnements cloud et on-premises
CDSW prône le « self-services data science ». Grace à sa variété de langages supportés, son format plateforme web et sa compatibilité cloud, l’un des slogans de CDSW est « access any data, anywhere ». Il permet aux data scientists de gérer leurs workflows de la planification au monitoring en passant par l’alerting.
On notera également dans CDSW, des fonctionnalités de mise à disposition des modèles via API, des systèmes d’expérimentation et du déploiement d’application web utilisant les modèles.
CDSW est une solution propriétaire qui se veut simple d’utilisation et efficace.
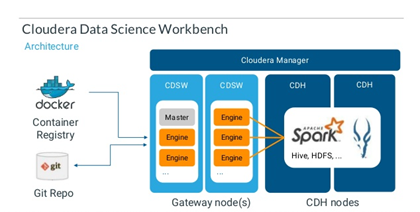
Comment installer la plate-forme de data science JupyterHub ?
JupyterHub peut être installé de plusieurs façons. Pour le souci de l’article, nous ne parlerons que de la méthode d’installation Kubernetes.
Les grandes étapes de l’installation de JupyterHub sont les suivantes :
- Déployer un cluster Kubernetes
- Installer Helm
- Installer JupyterHub
- Configurer JupyterHub
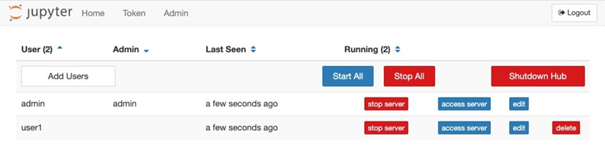
Malgré le fait que ce processus paraisse simple, la grande quantité de configurations rends la chose beaucoup plus complexe. JupyterHub permet par exemple de configurer le déploiement, les environnements utilisateurs, les ressources allouées aux utilisateurs, les stockages accessibles aux utilisateurs, la gestion des utilisateurs, les différentes méthodes d’authentification ou encore la sécurité pour n’en citer que quelques-uns.
Pour plus de détails sur le processus d’installation, vous pouvez vous rendre à l’adresse suivante : https://zero-to-jupyterhub.readthedocs.io/en/latest/
Méthode d’installation de CDSW
CDSW s’installe dans l’environnement Cloudera via les parcels et le Cloudera Manager. Son installation suit donc le mode classique d’installation de service.
Les grandes étapes de l’installation de CDSW sont les suivantes :
- Prérequis
- Configuration de Spark 2 (voir notre article sur la mise à jour de Spark 3.0)
- Configuration des variables d’environnement
- Téléchargement et installation des CSD CDSW
- Installation de la parcel
- Ajout du service CDSW
- Création du compte admin
- Configuration
Ici, la configuration est beaucoup plus simple et se présente comme pour un service classique. Une grande variété de clefs de configuration reste cependant présente.
(Pour plus de détails sur le processus d’installation, vous pouvez vous rendre à l’adresse suivante : https://docs.cloudera.com/documentation/data-science-workbench/1-6-x/topics/cdsw_install_parcel.html)
Installation et configuration : quels avantages liés à l’utilisation de JupyterHub ?
JupyterHub est une solution facilitant l’accès et l’administration des outils de DataScience destinés aux utilisateurs. Dans le cadre d’un environnement client, dont l’objectif était de remplacer son système d’utilisation Jupyter Notebook, nous avons déployé avec succès JupyterHub.
Ensuite, il faut configurer la solution pour qu’elle corresponde aux besoins attendus, ce qui peut lors de cette étape devenir compliqué.
La quantité des configurations, toutes ayant un nom assez peu identifiable, est très élevée. Pour configurer JupyterHub exactement comme souhaité, nous avons dû aller chercher des définitions et des exemples sur une grande partie, voir la totalité, des clefs de configuration présentes dans le fichier de configuration.
Pour bien administrer la plateforme, nous avons aussi dû nous renseigner sur son fonctionnement pour savoir à quoi correspondent les divers fichiers de configuration et de BDD présents. Nous avons configuré la solution pour utiliser le serveur de base de données où sont stockées les metadata du cluster afin de stocker ses propres données, de réduire l’utilisation de multiples fichiers de BDD sur la machine et de renforcer la sécurité des données.
Malgré les désagréments liés à ce très grand nombre de configurations, ils existent des avantages liés à l’utilisation JupyterHub. Grâce à sa grande communauté et à sa modularité, JupyterHub offre une large variété de modules, de configurations et de fonctionnalités complémentaires.
Une fois la solution fonctionnelle installée, on peut passer par la marketplace pour ajouter des modules d’interface graphique git pour les utilisateurs. C’est ce que nous avons fait au même titre que la configuration de la solution pour utiliser du LDAP, ainsi que sa sécurisation avec du TLS et des règles d’accès via des groupes AD.
Aussi, nous avons autorisé les comptes administrateurs à accéder aux serveurs utilisateurs afin de reproduire un comportement générant un bug et ainsi progresser plus facilement vers sa résolution.
Un point négatif a retenir tout de même est l’obstacle que représente l’ensemble de ces actions et le nombre très importants de configurations à réaliser. Ceci pouvant poser des problèmes dans l’activation de certains modules ou configurations. Si des modifications préalables empêchent la nouvelle configuration de fonctionner, il devient vite difficile de trouver la clé de configuration problématique.
Cependant une fois configuré, JupyterHub est une très bonne solution bien que très difficile à administrer et à configurer.
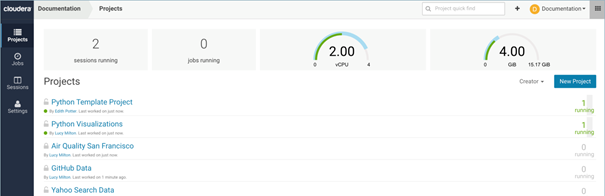
Retour d’expérience sur l’installation et la configuration de CDSW
Bien que l’installation reste simple, il faut néanmoins penser en amont au wildcard DNS. Sans quoi CDSW ne peut pas adresser les requêtes DNS interne.
L’administration de l’outil est relativement simple et réside dans quelques menus, plutôt clairs et concis. On déplorera par contre le manque de configurations avancées permettant plus de personnalisation.
L’intégration à Kerberos et LDAP est simple et bien pensé. Elle permet notamment d’interagir avec un environnement Hadoop Kerberisé nativement sans trop de configuration.
Coté notebook, ils tournent dans des pods Kubernetes sous-jacent à CDSW. Après plusieurs jours de recherche nous sommes parvenus, non sans mal, à utiliser une image Docker custom. Le principal problème est le nombre de layers que Cloudera a mis dans l’image de base, environ 127. Nous avons bloqué autour de 108 layers, en incluant des librairies de Machine Learning souhaitées. Il semble que Cloudera travaille à réduire le nombre de layer, en attendant il serait apprécié que le système soit plus ouvert ;).
Le tableau comparatif entre JupyterHub et CDSW
Pour notre comparatif, nous avons fait une évaluation des deux solutions sur les points suivants : simplicité d’utilisation, simplicité d’installation, personnalisation, configuration, performance, maintenabilité et administration, sécurité et enfin le coût. 10 étant la note la plus haute, 1 la plus faible.
| Critère | JupyterHub | CDSW |
| Simplicité d’utilisation | 7 | 8 |
| Simplicité d’installation | 5 | 7 |
| Personnalisation | 8 | 6 |
| Configuration | 9 | 7 |
| Performance | 7 | 8 |
| Maintenabilité et administration | 5 | 7 |
| Sécurité | 7 | 8 |
| Coût | 10 | 4 |
- JupyterHub et CDSW sont tous les deux assez simples à utiliser, même si CDSW possède un avantage grâce à son interface beaucoup plus simple d’accès.
- Les dépendances et configurations nécessaires pour avoir une plateforme JupyterHub sont plutôt nombreuses, rendant le déploiement complet d’une plateforme JupyterHub fonctionnelle assez long. D’un autre côté, l’installation d’un service CDSW est bien plus rapide.
- CDSW permet quelques personnalisations mais elles sont loin d’être aussi nombreuses que JupyterHub avec ses modules et sa communauté.
- JupyterHub possède une grande variété de configurations et la possibilité d’ajouter des configurations supplémentaires via les modules communautaires. CDSW, quant à lui, possède de base d’assez bonnes possibilités de configuration et de bonnes fonctionnalités mais nettement moins que la solution JupyterHub.
- Les deux solutions possèdent d’assez bonnes performances mais l’interconnexion facilitée avec les autres services du cluster donne à CDSW un léger avantage.
- CDSW profite des droits d’administration et du management des services offert par le Cloudera Manager. Ce qui lui donne un avantage sur JupyterHub et ses nombreuses configurations à maîtriser avant de pouvoir facilement administrer et s’occuper des problèmes de la solution.
- Les deux solutions proposent des possibilités de sécurisation assez poussées mais CDSW gagne un petit avantage grâce à sa facilité d’intégration avec les sécurités déjà présentes dans le cluster.
- JupyterHub est une solution open source alors que CDSW est une solution propriétaire qui devient assez couteuse si on prend le support.
Quelle solution choisir entre JupyterHub et CDSW en définitive ?
JupyterHub est une solution à faible coût offrant une grande liberté de configuration et d’amélioration, mais difficile à administrer.
CDSW est une solution moins libre et plus chère mais qui reste solide et stable sur beaucoup de critères, tout en restant facile à administrer.
La question de cet article était de savoir quelle solution choisir en fonction des besoins et ressources à notre disposition.
Si l’on recherche une solution robuste et simple à prendre en main, CDSW reste le choix idéal. C’est une solution adaptée pour les entreprises ayant les moyens d’investir dans une solution conçue pour s’intégrer facilement au SI.
Si l’on recherche une solution plus libre, dotées de plus de possibilité et budgétairement accessible, JupyterHub est la solution idéale. JupyterHub peut se présenter comme un bon choix pour la recherche ou le développement dans des entreprises ou des laboratoires qui ne sont pas directement lié à la production ou qui n’ont pas de budget à investir dans une solution propriétaire. Attention tout de même, l’administration sera moins aisée et donc plus difficile à prendre en main.
Les deux solutions restent très intéressantes toutes les deux avec leurs avantages et leurs défauts, mais il en existe d’autres pouvant répondre à des besoins plus spécifiques. Avec l’arrivée de la nouvelle plateforme Cloudera dans le Cloud, la Cloudera Data Platform, il sera possible de faire du CDSW à la volé via CML. Le produit CML pour Cloudera Machine Learning regroupe l’ensemble de CDSW dans un système Cloud et conteneurisé.
Cet outil prometteur sera à surveiller de près.





